Packages R pour controler son travail et ainsi mieux optimiser, réutiliser et communiquer autour de ses analyses
Journées du PEPI IBIS 2023
Cédric Midoux 
PROSE & MaIAGE
Philippe Ruiz
MEDIS
September 15, 2023
Reproductibilité, pour quoi faire ?

Derrière la reproductibilité :
la transparence dans la recherche

Expliquer pour justifier et comprendre
Refaire pour vérifier, corriger et réutiliser
- Vous oblige à vérifier votre travail (partage des données + code)
- Votre futur vous-même vous remerciera
- Et vos collègues aussi
- En étant reproductible, vous renforcez votre crédibilité et votre réputation
- La reproductibilité favorise la confiance dans le processus scientifique
Vous contribuez à l’accélération des progrès scientifiques !
et vous ne perdez pas de temps …

Un des principes FAIR

Spectre de la reproctibilité

- Ne pas avoir peur d’avancer à petit pas, marche après marche
- Processus itératif et progressif
Controler ses sources (script & données)

Contrôle des versions (git)

- Enregistrer les modifications apportées à un ensemble de fichiers
- Suivre l’historique et revoir toutes les modifications
- Revenir à des versions antérieures
- Travailler collaborativement sur des fonctionnalités parallèles
Ça marche avec des scripts et des codes, des protocoles & de la documentation, des rapports, n’importe quel document !
Cycle de vie de la donnée & PGD
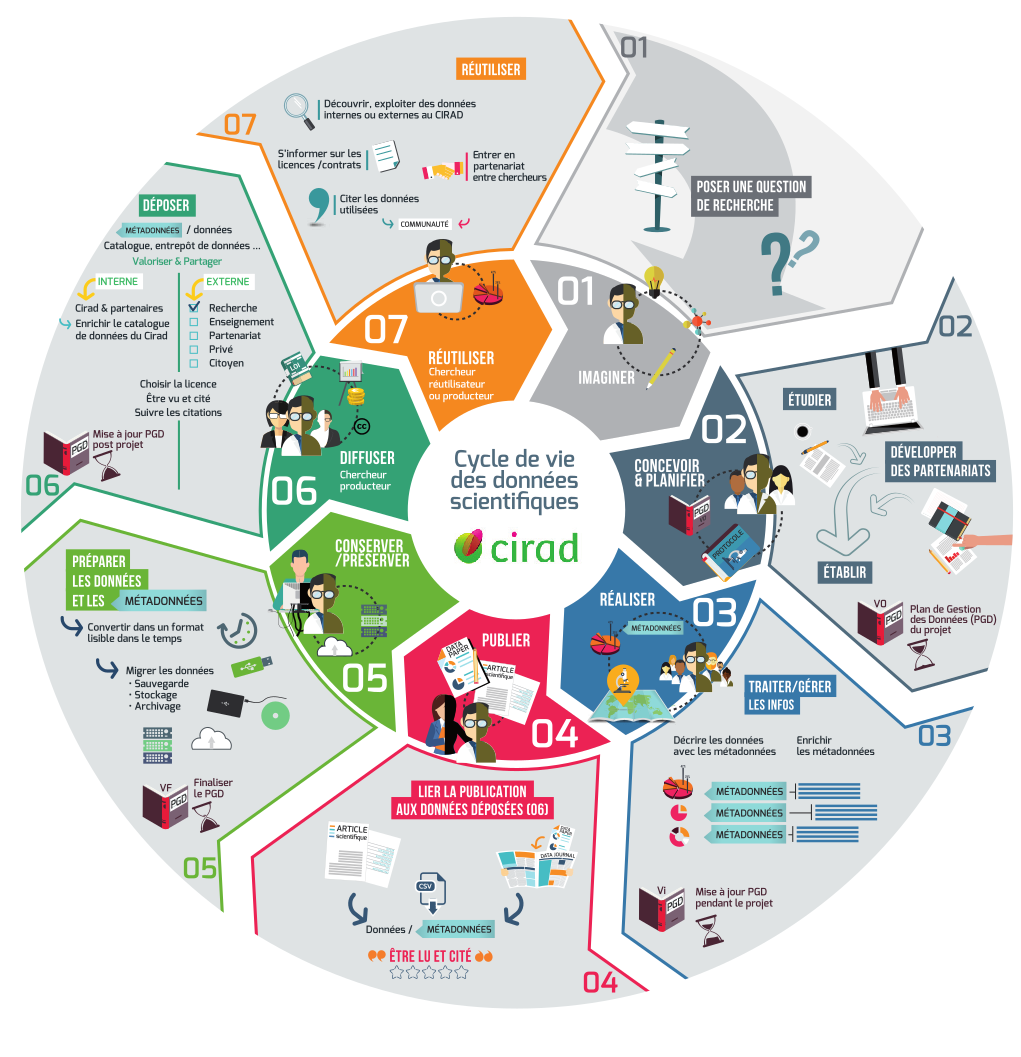
Open Data 5★
OL★ : Open LicenseRE★ : machine REadableOF★ : Open FormatURI★ : Uniform Resource IdentifierLD★ : Linked Data
Travailler dans un environnement controlé

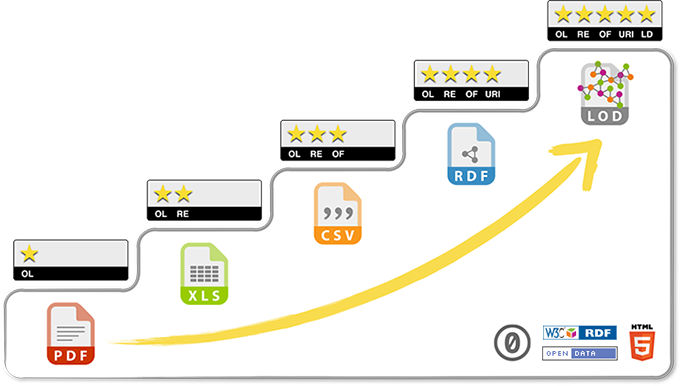
Constat
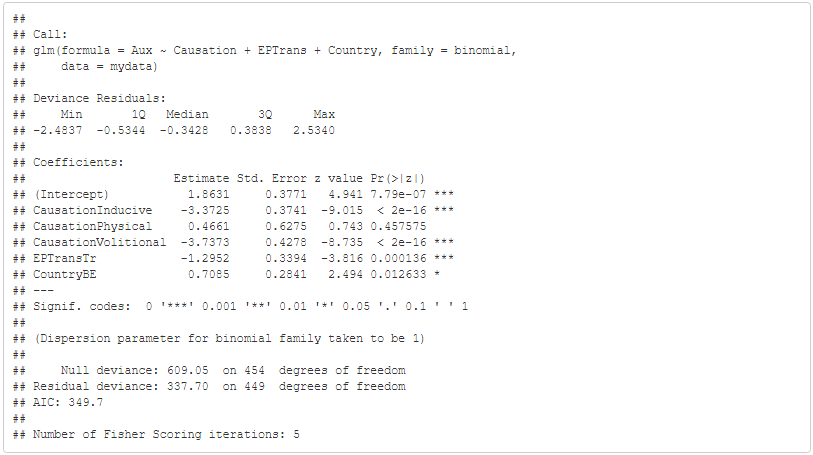
While preparing a manuscript, to our surprise, attempts by team members to replicate these results produced different calculated NMR chemical shifts despite using the same Gaussian files and the same procedure outlined by Willoughby et al. […] these conclusions were based on chemical shifts that appeared to depend on the computer system on which step 15 of that protocol was performed.
[7]
Travailler avec un workflow d’analyses controlé

Data Science
targets
Ce package permet de structurer un pipeline d’analyses sous une forme bien précise composé d’étapes écrit dans un schéma global (workflow). On pourrait le comparer à un petit snakemake ou nextflow sous R.
Facilite la parallélisation.
Philosophie
Écrire un pipeline d’analyse sous la forme d’un workflow dont chacune des étapes est reliée et dépendante les une des autres. Le but est de structurer le workflow en étapes prédéfinies et toutes structurées de la même manière (une entrée, une fonction, une sortie) et dont leur état est référencé lors de l’exécution du pipeline.
Schéma
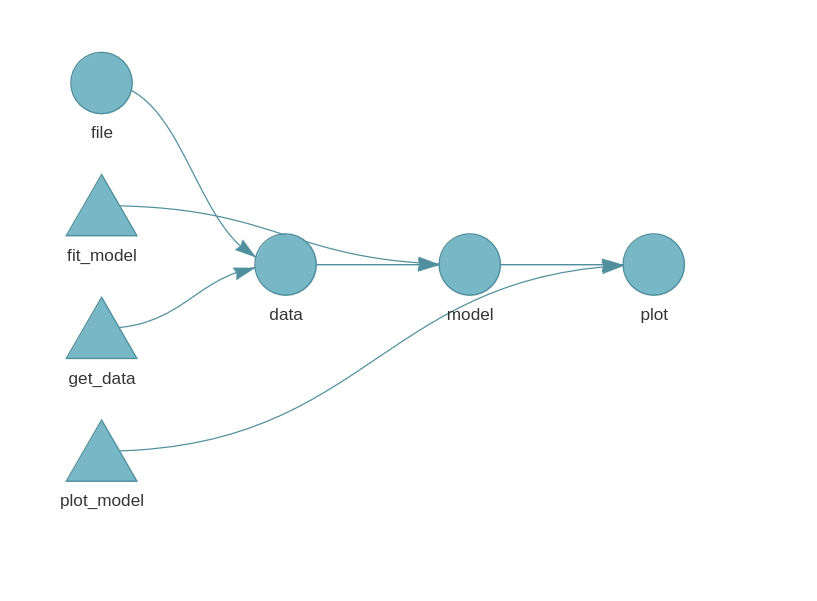
Structure du projet
├── _targets.R : le script d'execution principal
├── data/
│ ├── robject.RData : un objet R
│ ├── data.csv : les données
├── R/
│ ├── functionsMain.R : les fonctions principales utilisées pour réaliser des analyses
│ ├── functionsPlots.R : les fonctions utilisées pour réaliser les graphiques
│ ├── functionsTests.R : les fonctions secondaires
├── _output/
│ ├── output.csv : fichiers de sortie
├── _targets/
│ ├── meta/
│ ├── objects/
│ ├── user/
│ ├── workspaces/_targets.R
Execution du pipeline
La fonction tar_make() exécute le pipeline dans son ensemble en respectant l’ordre des étapes écrites dans le fichier _targets.R.
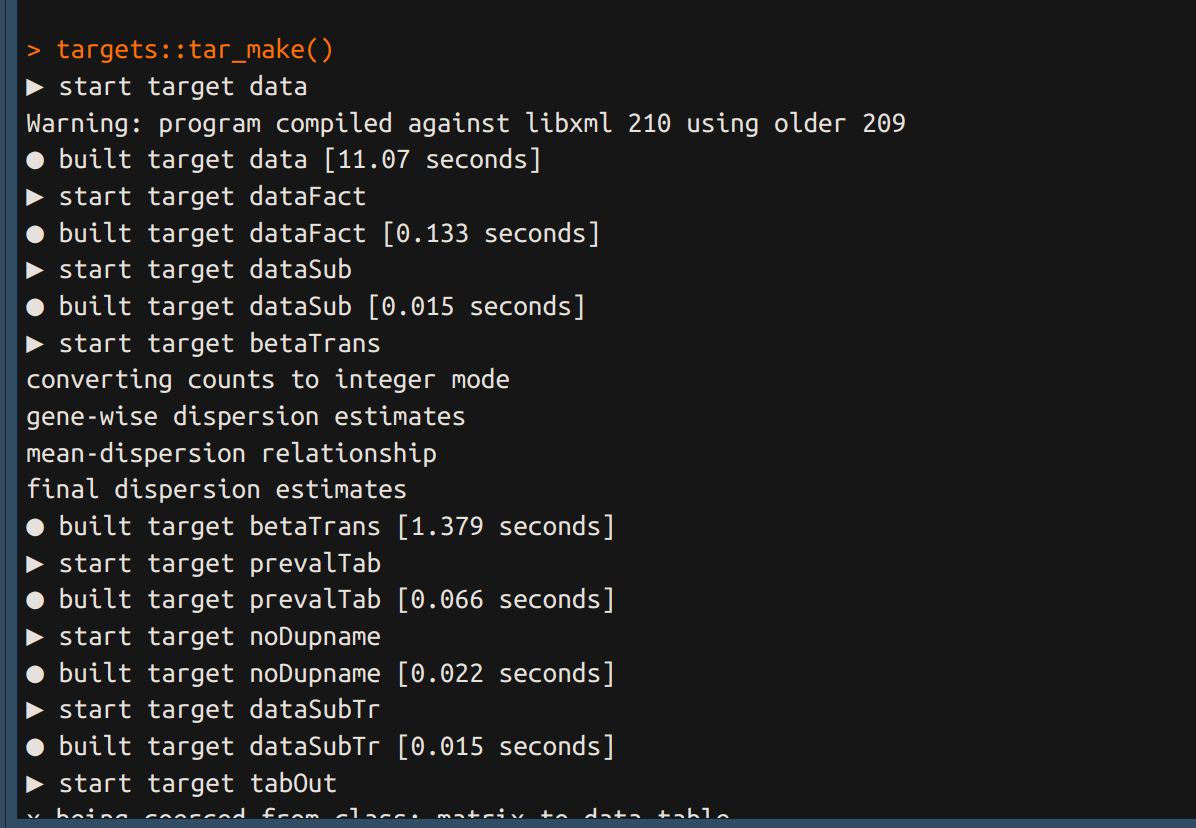
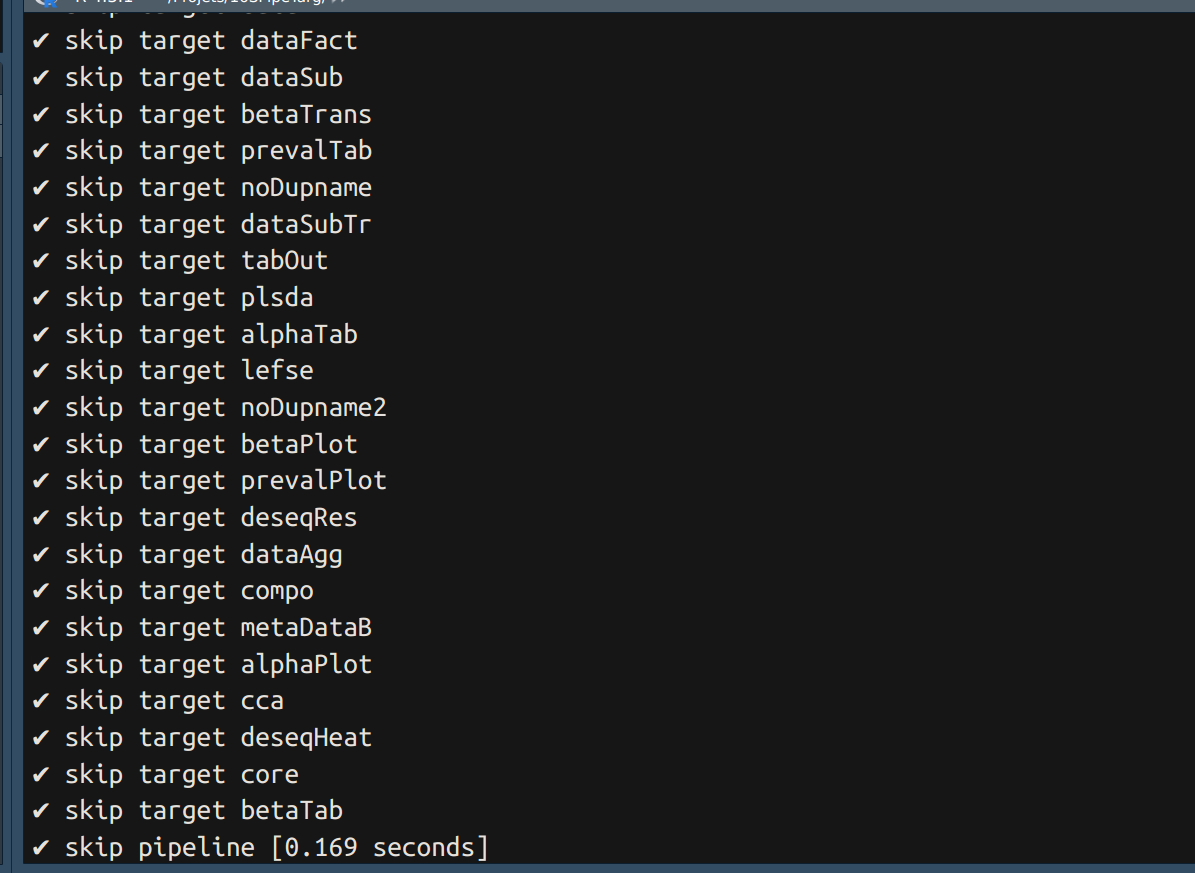
Ré-execution du pipeline
Quand on exécutera à nouveau le pipeline seules les étapes ayant été modifiées seront de nouveau exécutées.
Visualisation du pipeline
La fonction tar_visnetwork() affiche un DAG du pipeline au temps t, mettant en évidence l’état des étapes (done, waiting, error).

Visualisation des objets de sortie
Contrairement à une utilisation classique de R, les objets ne sont pas stockés dans l’environnent global mais dans les dossiers _targets > objects. Il s’agit de fichiers compilés lisibles uniquement par targets via la commande tar_read(object):
Résultats
Appeler les objets de sortie de targets dans les chunks d’un fichier qmd:
ou
Controler ses supports de communication

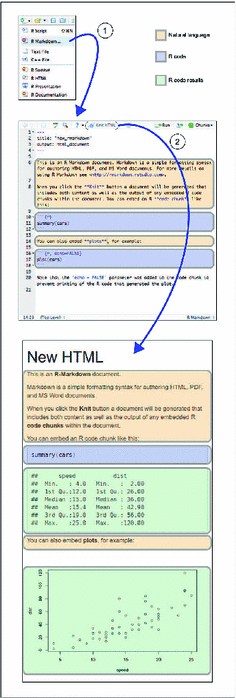
RMarkdown
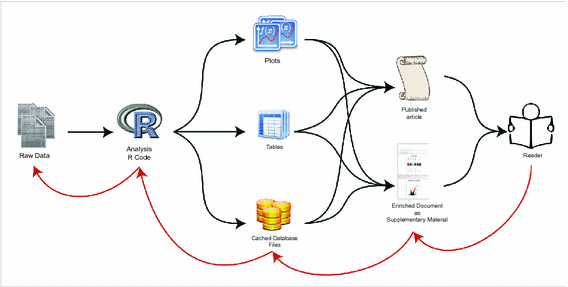
Unifier en unique document contexte, code, résultat, interprétation pour assure la cohérence des analyses …
quarto
- Successeur de
Rmarkdown - Multi langages (R, Python, Julia, Observable)
- Documents de type rapports paginés, documents HTML, sites web, livres, slides
- Interactivité
- Export en
html,pdf,docx,ePub, …
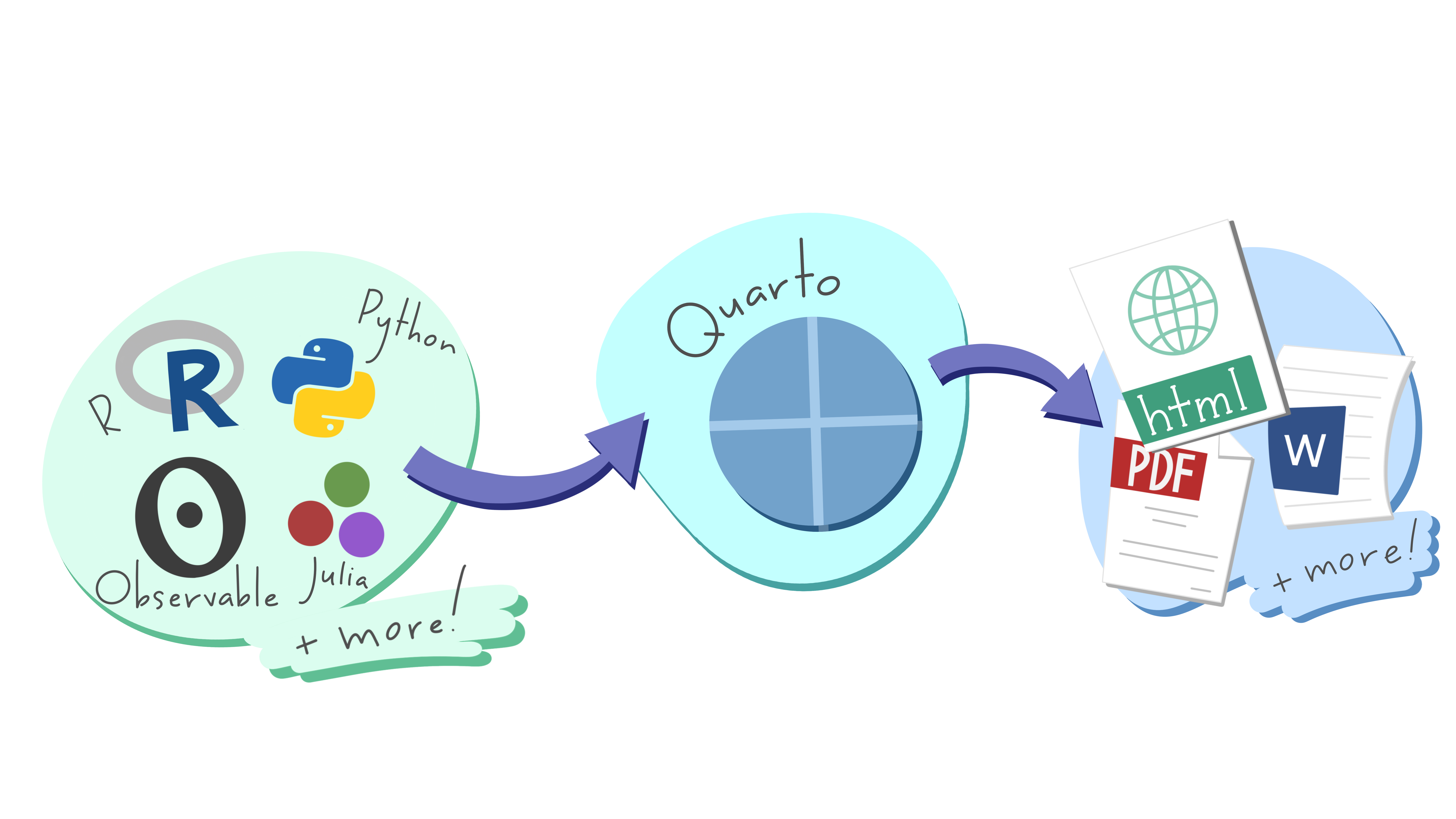
An open-source scientific and technical publishing system
Quarto - exemples
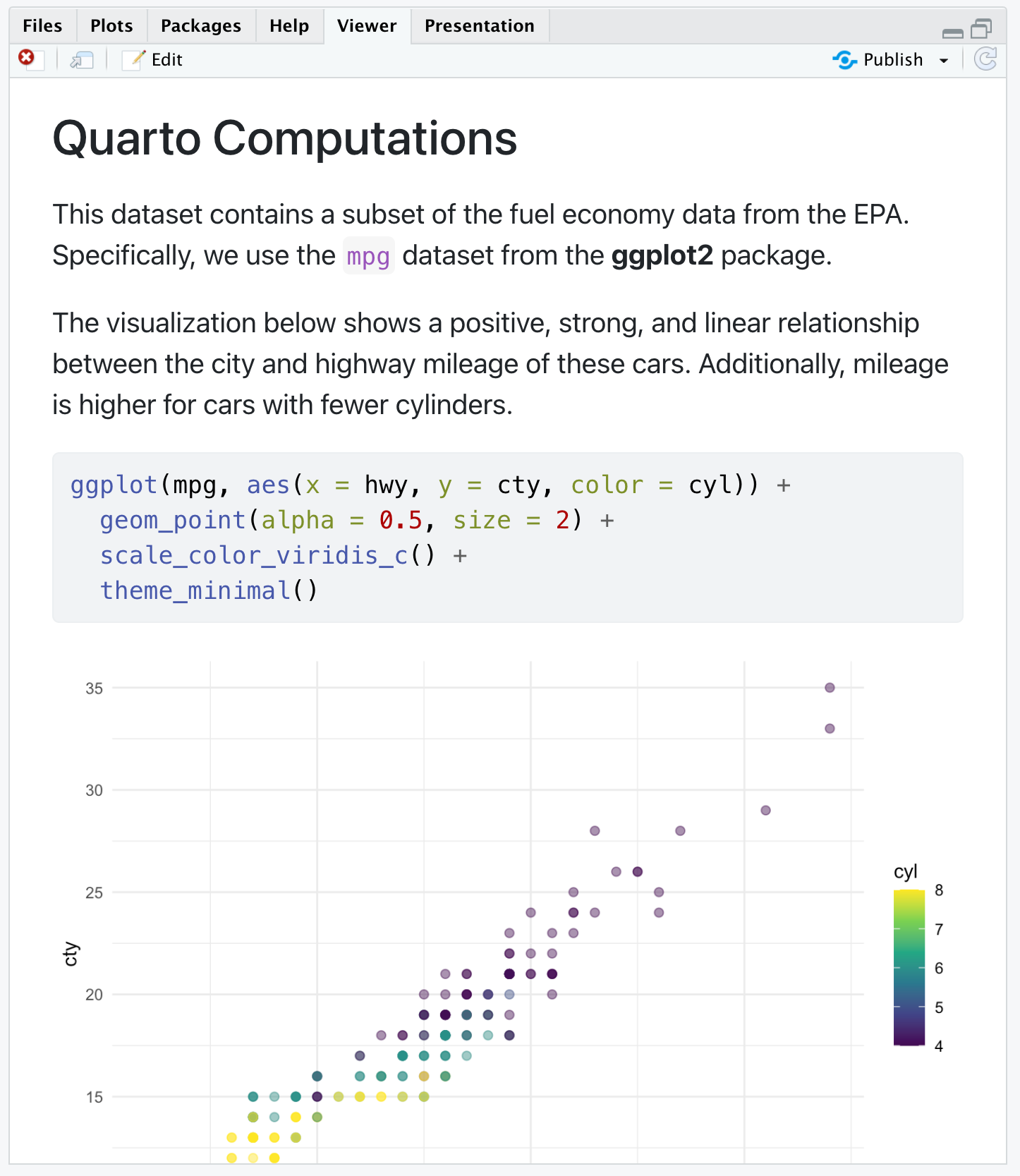
---
title: "Quarto Computations"
---
This dataset contains a subset of the fuel economy data from the EPA.
Specifically, we use the `mpg` dataset from the **ggplot2** package.
```{r}
#| label: load-packages
#| echo: false
library(ggplot2)
```
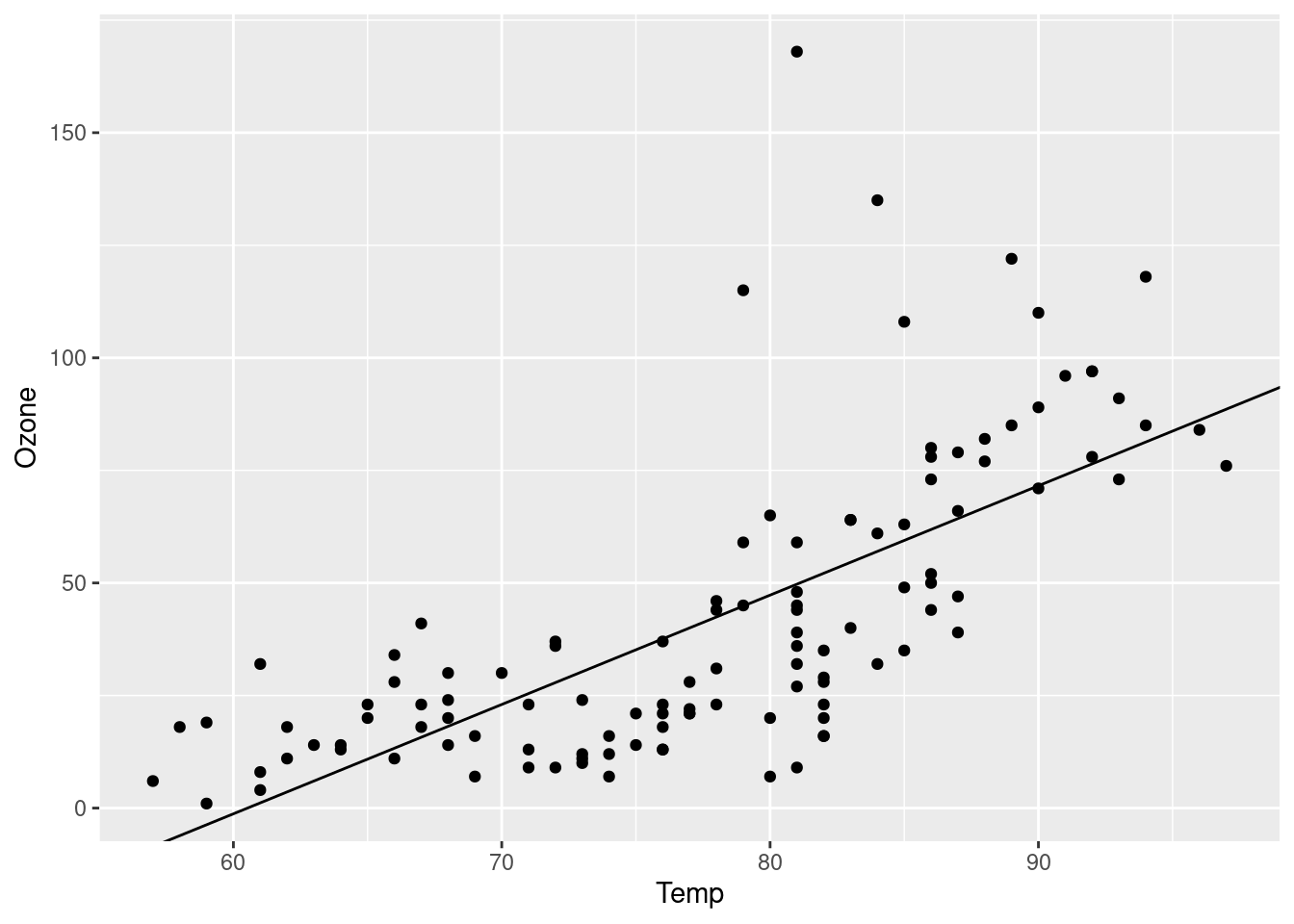
The visualization below shows a positive, strong, and linear relationship between the city and highway mileage of these cars.
Additionally, mileage is higher for cars with fewer cylinders.
```{r}
#| label: scatterplot
ggplot(mpg, aes(x = hwy, y = cty, color = cyl)) +
geom_point(alpha = 0.5, size = 2) +
scale_color_viridis_c() +
theme_minimal()
```
Code highlighting
Diffusion en CI/CD : GitLab Pages
.gitlab-ci.yml
# The Docker image that will be used to build your app
image: rocker/verse:4.2
# Functions that should be executed before the build script is run
before_script:
- quarto install extension davidcarayon/quarto-inrae-extension --no-prompt
pages:
script:
- quarto render
artifacts:
paths:
# The folder that contains the files to be exposed at the Page URL
- public
rules:
# This ensures that only pushes to the default branch will trigger
# a pages deploy
- if: $CI_COMMIT_REF_NAME == $CI_DEFAULT_BRANCHEt si on mélange tout ça
Step by step


Comment ça marche ?