Solution
ips_data <- readr::read_tsv("Data/ips_data.tsv")
academy_data <- readr::read_tsv("Data/academy_data.tsv")Mahendra Mariadassou 
Christelle Hennequet-Antier
The goals of this vignette is to provide additionnal challenges to help you consolidate your grasp of tidyverse verbs. It will also allow us to introduce some useful verbs that were not covered in the vignettes like slice() and rename().
For this tutorial, we’ll use the IPS data from French high schools. The data were recovered from open data platform of the Ministère de l’Éducation, des Sports et de la Jeunesse here in csv format.
We slightly preprocessed them to challenge you with (hopefully) interesting questions.
The data are stored in two flat tsv files. Use one of the read_*() from the readr package to import them as ips_data and academy_data.
ips_data <- readr::read_tsv("Data/ips_data.tsv")
academy_data <- readr::read_tsv("Data/academy_data.tsv")Each dataset consists of tabular data with several colums.
academy_data has 6 variables:
Académie: academy (administrative division for higher education) of the high schoolCode du département: departement numberDépartement: departement (medium scale administrative division) of the high schoolUAI: high school unique IDNom de l'établissement: institution nameCode INSEE de la commune: INSEE code of the cityNom de la commune: city nameSecteur: whether the school is public or privé sous contratips_data has 7 variables:
Rentrée scolaire: academic yearUAI: high school unique IDIPS Ensemble GT-PRO: mean IPS for students in both Voie Générale et Technologique (hereafter GT) and Voie Professionnelle (hereafter PRO)IPS voie GT: mean IPS for GT studentsIPS voie PRO: mean IPS for PRO studentsEcart-type de l'IPS voie GT: standard deviation of the IPS for GT studentsEcart-type de l'IPS voie PRO: standard deviation of the IPS for PRO studentsThe long variable names are informative but cumbersome to type. We’d like to replace them with shorter names. We’re also interested in neither the Code INSEE de la commune nor the department information.
Look up the rename() function, remove superfluous variables and replace academy_data and ips_data with version with shorter names.
This is one possible solution, but you can come up with other names.
## Academy data
academy_data <- academy_data |>
## remove superfluous columns
select(-c(`Code du département`, `Département`, `Code INSEE de la commune`)) |>
## use shorter names
rename(
Academy = `Académie`,
Institution = `Nom de l'établissment`,
Institution_ID = UAI,
Sector = Secteur,
City = `Nom de la commune`,
)
ips_data <- ips_data |>
rename(
Academic_Year = `Rentrée scolaire`,
Institution_ID = UAI,
IPS = `IPS Ensemble GT-PRO`,
IPS_gt = `IPS voie GT`,
IPS_pro = `IPS voie PRO`,
IPS_sd_gt = `Ecart-type de l'IPS voie GT`,
IPS_sd_pro = `Ecart-type de l'IPS voie PRO`
)Note that you can only also rename and select at the same time, as the following code shows:
academy_data <- academy_data |>
select(
Academy = `Académie`,
Institution = `Nom de l'établissment`,
Institution_ID = UAI,
Sector = Secteur,
City = `Nom de la commune`,
)We’d like to perform a few checks on the data.
Find the fraction of missing values for the standard deviation of the IPS score for each year. Do the values before 2019 make sense ? What about those after 2019 ?
To perfom this computation, we
IPS_sd_gt and IPS_sd_pro by transforming NA to 1 and other values to 0 computing the mean.ips_data |>
## Group the data by year
group_by(Academic_Year) |>
## Compute the fraction of missing values
summarize(frac_na_sd_gt = mean(is.na(IPS_sd_gt)),
frac_na_sd_pro = mean(is.na(IPS_sd_pro)))# A tibble: 6 × 3
Academic_Year frac_na_sd_gt frac_na_sd_pro
<chr> <dbl> <dbl>
1 2016-2017 1 1
2 2017-2018 1 1
3 2018-2019 1 1
4 2019-2020 0.320 0.422
5 2020-2021 0.315 0.421
6 2021-2022 0.314 0.421We find that 100% of values were missing before the year 2019-2020. This is expected as this metric was not collected before 2019. Afterwards, we have roughly 31% of missing values for IPS_sd_gt and 42% for IPS_sd_pro. This corresponds, for the former, to the fraction of high schools with no Voie Professionnelle and, for the latter, with no Voie Générale et Technologique. The remaining 27% are high schools offering both Voies.
We’ve seen previously that a high school can be limited to Voie Professionnelle, limited to Voie Générale et Technologique or have both. We’d like to code this information as a factor with 3 levels: GT, PRO and Mixed. Likewise, we’d like to recode the Sector as something shorter. We can do that using case_when() and if_else().
Add a public_type column to the data frame that characterizes the students in the high school. It should take 3 values:
"gt" if the school only has GT students"mixed" if the school only has both GT students and PRO students"pro" if the school only has PRO studentsRecode the Sector column so that the two values it takes are:
"public" if the high school is public
"private" if the high school is private
We use case_when() for the public_type variable.
ips_data <- ips_data |>
mutate(public_type = case_when(
## Scores available for both GT and PRO students, the school is mixed
!is.na(IPS_gt) & !is.na(IPS_pro) ~ "mixed",
## Scores available for GT students, the school is pro
!is.na(IPS_gt) ~ "gt",
## Scores available for PRO students, the school is pro
!is.na(IPS_pro) ~ "pro",
))For Sector, the information is already present but takes values "public" and "privé sous contrat" and we just want to change "privé sous contrat" to "private" and keep the rest unchanged.
academy_data <- academy_data |>
mutate(Sector = if_else(Sector == "privé sous contrat", "private", "public"))If we try to join the tables with inner_join(academy_data, ips_data), we end up with a strange message:
Detected an unexpected many-to-many relationship between `x`
and `y`.
ℹ Row 1 of `x` matches multiple rows in `y`.
ℹ Row 19 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set
`relationship = "many-to-many"` to silence this warning.What causes the problems ? Identify the source of the problem.
Do you expect a single row from academy_data to match multiple rows in ips_data ? And a single row from ips_data to match mutiple rows in academy_data ?
Each high school is represented by several academic years so a single row from academy_data should match multiple rows in ips_data. However, each high school should only be represented once in academy_data. Let’s look at row 19 of ips_data and extract its matching rows in academy_data. This is a textbook example for a filtering join.
semi_join(academy_data, ips_data[19, ])# A tibble: 3 × 5
Academy Institution_ID Institution City Sector
<chr> <chr> <chr> <chr> <chr>
1 MARTINIQUE 9720091S LYCEE PROFESSIONNEL LEOPOLD BISSOL LE L… public
2 MARTINIQUE 9720091S LYCEE PROFESSIONNEL LEOPOLD BISSOL (LY… LE L… public
3 MARTINIQUE 9720091S LYCEE PROFESSIONNEL LEOPOLD BISSOL LYC… LE L… publicWe see that the high school with identifier 9720091S is present three times with three different names, probably because it changed names during the time period (and because the name was mispelled in one record). We may have more records like that in our data.
Now that we identified the source of the problem, we can fix it (by keeping only the first record for each high school) and join the tables.
Look up distinct(). Keep only one record per high school (the first one) and join the table.
We use distinct() with the option .keep_all = TRUE to keep only one record per high school but keep all variables for those records
data <- academy_data |>
## keep only one record per high school
distinct(Institution_ID, .keep_all = TRUE) |>
## join with the IPS data
inner_join(ips_data)We’d like to focus on Paris high schools to study the impact of the Affelnet reform. We’re going to create a subset specifically tailored to that question.
Select parisian public high schools that only have GT students and for which we have 6 years of data and keep only the informative columns. Store the results in a new variable paris_data.
Create intermediate variables to count the number of records per school (and optionally whether a high school was always public during the time period).
We must perform the following steps:
mutate() rather than summarize() after the group_by(). We could also use add_count() which does exactly the same thing.Sector, public_type (because all schools are public and host only GT students), IPS or IPS_gt (the two are redundant since the schools are GT), IPS_pro and IPS_sd_pro (the school have no PRO students).paris_data <- data |>
## select parisian high schools from the public sector
filter(Academy == "PARIS", Sector == "public") |>
## add number of record and public type for each high school
group_by(Institution_ID) |>
mutate(is_gt = all(public_type == "gt"),
n_records = n()) |>
## keep only the requested high schools
filter(is_gt, n_records == 6) |>
## remove uninformative colmuns
select(-Sector, -IPS, -IPS_pro, -IPS_sd_pro, -public_type, -is_gt, -n_records)We want to compare the mean IPS between public and private high schools.
In which academies (if any) is the IPS higher (on average) for public high schools than for private ones ?
We first need to compute the average IPS score per academy per sector. The question doesn’t specify it but we’re going first to compute the average IPS per school before doing the aggregation. Then we need to pivot the data to have two columns (one for public and one for private) before counting the results.
data |>
## We need to add Academy and Sector to keep them in the tibble for further computations
summarise(IPS = mean(IPS), .by = c(Academy, Sector, Institution_ID)) |>
## Summarise at the academy level
summarise(IPS = mean(IPS), .by = c(Academy, Sector)) |>
## Pivot according to the sector
pivot_wider(values_from = IPS, names_from = Sector) |>
filter(private < public)# A tibble: 2 × 3
Academy public private
<chr> <dbl> <dbl>
1 GUADELOUPE 870. 843.
2 BESANCON 1000. 984.Before focusing on the Affelnet reform, we want to identify the most privileged high school in each academy.
Find the high school with the highest IPS in each academy for the year 2020-2022, then the top 5, then the second highest. You can look up slice_*() functions to help you.
We’re going to group the data by academy and sort them by IPS before using slice(1) or slice_head(1)for the highest IPS.
data |>
filter(Academic_Year == "2021-2022") |>
group_by(Academy) |>
arrange(desc(IPS)) |>
slice(1)# A tibble: 32 × 12
# Groups: Academy [32]
Academy Institution_ID Institution City Sector Academic_Year IPS_gt IPS_pro
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 AIX-MAR… 0131323T LYCEE GENE… MARS… priva… 2021-2022 1515 NA
2 AMIENS 0601149Y LYCEE GENE… SENL… priva… 2021-2022 1392 NA
3 BESANCON 0900030U LYCEE GENE… BELF… priva… 2021-2022 1338 NA
4 BORDEAUX 0331493U LYCEE GENE… BORD… priva… 2021-2022 1447 NA
5 CAEN 0141161L LYCEE GENE… CAEN priva… 2021-2022 1317 NA
6 CLERMON… 0631847R LYCEE GENE… CLER… priva… 2021-2022 1447 NA
7 CORSE 7200073S LYCEE GENE… BAST… priva… 2021-2022 1261 NA
8 CRETEIL 0940880W LYCEE GENE… NOGE… priva… 2021-2022 1492 NA
9 DIJON 0211074D LYCEE GENE… DIJON priva… 2021-2022 1346 NA
10 GRENOBLE 0382863F LYCEE POLY… MEYL… public 2021-2022 1446 1181
# ℹ 22 more rows
# ℹ 4 more variables: IPS <dbl>, IPS_sd_gt <dbl>, IPS_sd_pro <dbl>,
# public_type <chr>We can also use slice_head(5)for the five highest IPS per academy
data |>
filter(Academic_Year == "2021-2022") |>
group_by(Academy) |>
arrange(desc(IPS)) |>
slice_head(n = 5)# A tibble: 160 × 12
# Groups: Academy [32]
Academy Institution_ID Institution City Sector Academic_Year IPS_gt IPS_pro
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 AIX-MAR… 0131323T LYCEE GENE… MARS… priva… 2021-2022 1515 NA
2 AIX-MAR… 0131324U LYCEE GENE… MARS… priva… 2021-2022 1482 NA
3 AIX-MAR… 0131319N LYCEE GENE… AIX … priva… 2021-2022 1468 NA
4 AIX-MAR… 0132810J LYCEE GENE… AUBA… priva… 2021-2022 1418 NA
5 AIX-MAR… 0133525L LYCEE GENE… AIX … public 2021-2022 1388 NA
6 AMIENS 0601149Y LYCEE GENE… SENL… priva… 2021-2022 1392 NA
7 AMIENS 0602070Z LYCEE D EN… MORT… priva… 2021-2022 1377 NA
8 AMIENS 0601701Y LYCEE GENE… COMP… priva… 2021-2022 1360 NA
9 AMIENS 0600009J LYCEE GENE… CHAN… public 2021-2022 1292 NA
10 AMIENS 0801742J LYCEE D EN… AMIE… priva… 2021-2022 1276 NA
# ℹ 150 more rows
# ℹ 4 more variables: IPS <dbl>, IPS_sd_gt <dbl>, IPS_sd_pro <dbl>,
# public_type <chr>And slice slice(2) for the second highest IPS per academy
data |>
filter(Academic_Year == "2021-2022") |>
group_by(Academy) |>
arrange(desc(IPS)) |>
slice(2)# A tibble: 32 × 12
# Groups: Academy [32]
Academy Institution_ID Institution City Sector Academic_Year IPS_gt IPS_pro
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 AIX-MAR… 0131324U LYCEE GENE… MARS… priva… 2021-2022 1482 NA
2 AMIENS 0602070Z LYCEE D EN… MORT… priva… 2021-2022 1377 NA
3 BESANCON 0251028G LYCEE GENE… BESA… priva… 2021-2022 1256 NA
4 BORDEAUX 0331491S LYCEE GENE… BORD… priva… 2021-2022 1409 NA
5 CAEN 0142059M LYCEE GENE… CAEN public 2021-2022 1304 NA
6 CLERMON… 0631075B LYCEE GENE… CLER… priva… 2021-2022 1327 NA
7 CORSE 7200021K LYCEE GENE… CORTE public 2021-2022 1174 NA
8 CRETEIL 0940877T LYCEE GENE… VINC… priva… 2021-2022 1482 NA
9 DIJON 0211928G LYCEE GENE… DIJON public 2021-2022 1324 NA
10 GRENOBLE 0730759D LYCEE GENE… AIX … priva… 2021-2022 1406 NA
# ℹ 22 more rows
# ℹ 4 more variables: IPS <dbl>, IPS_sd_gt <dbl>, IPS_sd_pro <dbl>,
# public_type <chr>We want to assess the effect of the affelnet reform by comparing the IPS score and the heterogeneity of the IPS between 2020-2021 and 2021-2022. We first need to format like below:
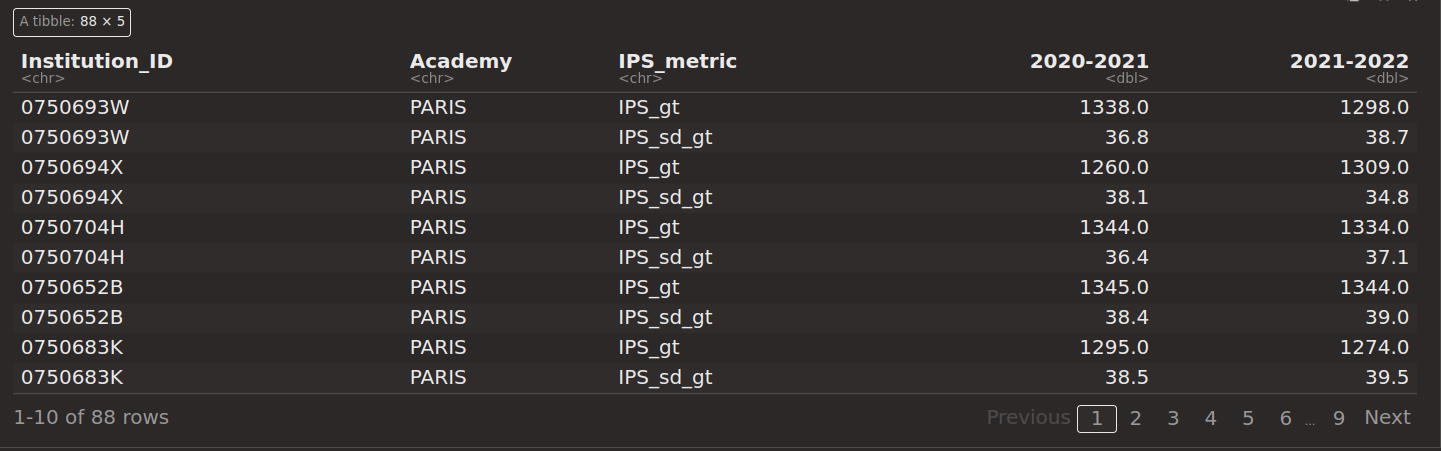
Filter and transform paris_data so it looks like the previous table. I removed the columns Institution and City from the screenshot but you should keep them.
Looking carefully at the expected result:
pivot_longer() to change the two columns IPS_gt and IPS_gt_sd into two recordspivot_wider() to change the two rows corresponding to years 2020-2021 and 2021-2022 into two columns.paris_data <- paris_data |>
filter(Academic_Year %in% c("2020-2021", "2021-2022")) |>
pivot_longer(cols = IPS_gt:IPS_sd_gt,
names_to = "IPS_metric",
values_to = "Value") |>
pivot_wider(values_from = Value, names_from = Academic_Year)You’re now ready to reproduce the following graphs.
ggplot(paris_data |> filter(IPS_metric == "IPS_gt"),
aes(x = `2020-2021`, `2021-2022`)) +
geom_point() +
geom_abline(slope = 1, intercept = 0, color = "grey20") +
geom_smooth(method = "lm", se = FALSE) +
labs(x = "IPS in 2021", y = "IPS in 2022") +
coord_equal() +
theme_bw()
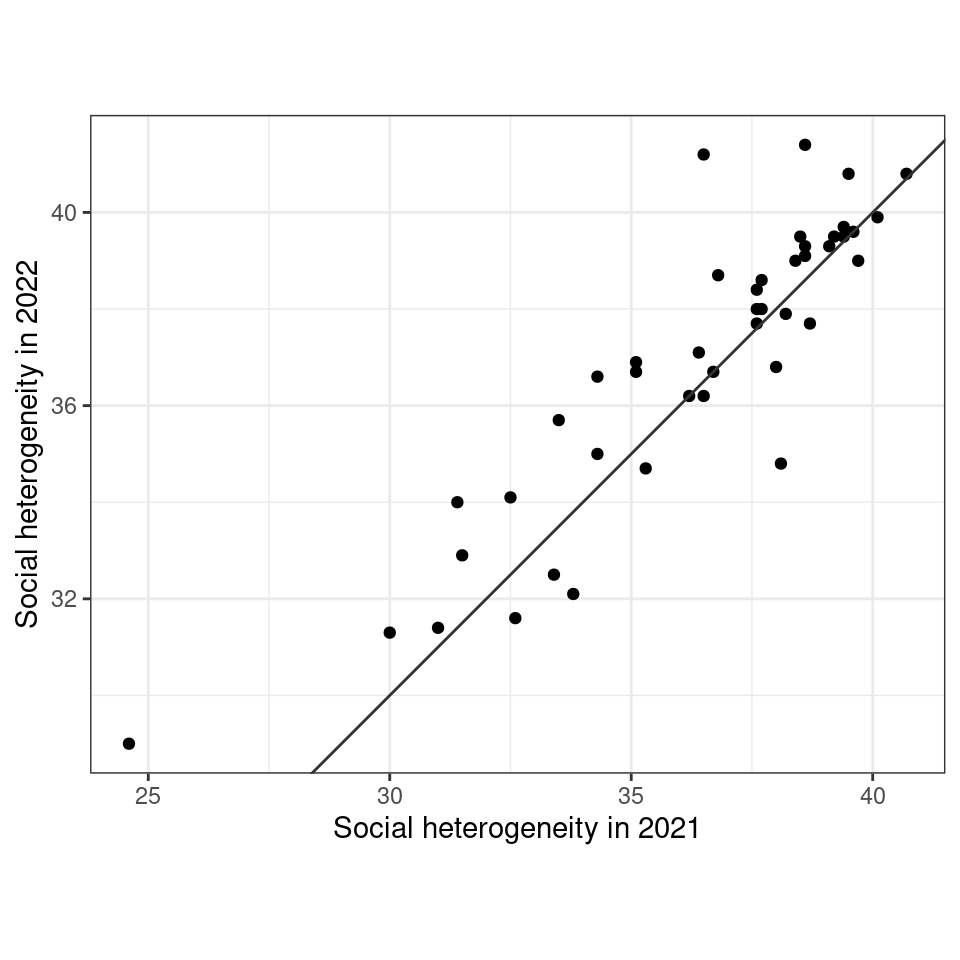
ggplot(paris_data |> filter(IPS_metric == "IPS_sd_gt"),
aes(x = `2020-2021`, `2021-2022`)) +
geom_point() +
geom_abline(slope = 1, intercept = 0, color = "grey20") +
labs(x = "Social heterogeneity in 2021", y = "Social heterogeneity in 2022") +
coord_equal() +
theme_bw()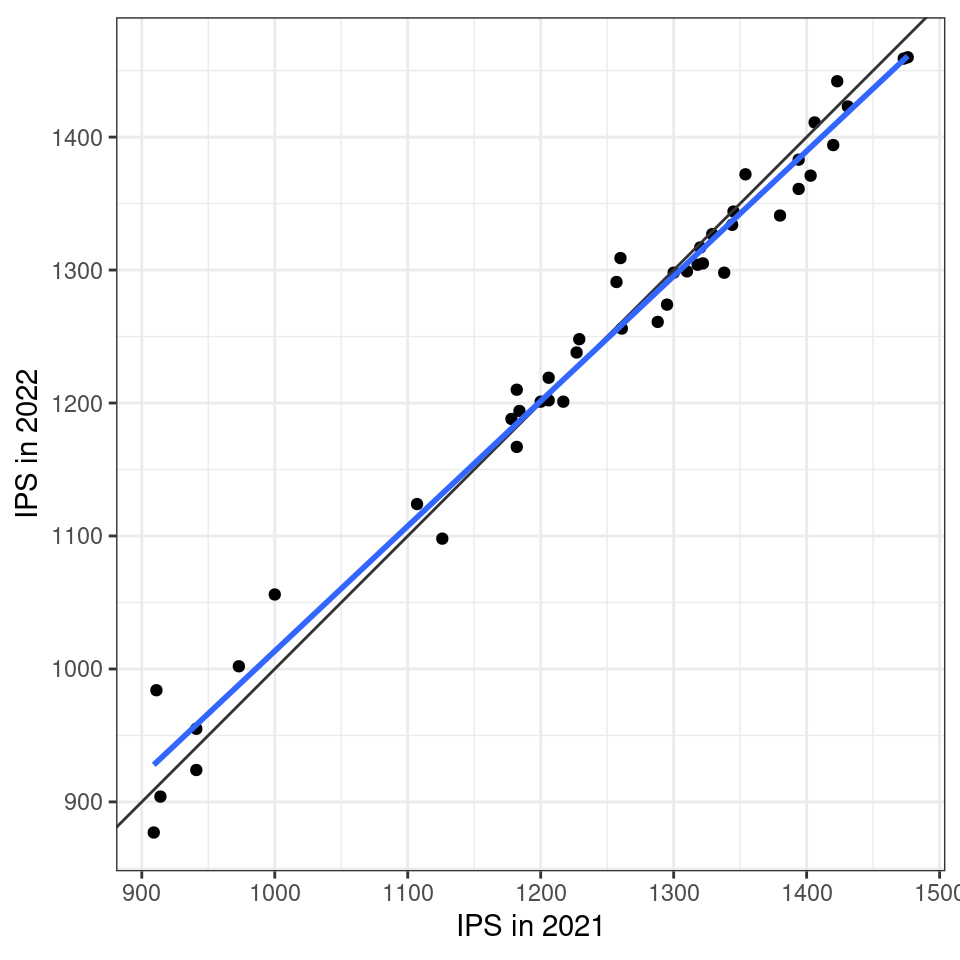
A work by Migale Bioinformatics Facility
Université Paris-Saclay, INRAE, MaIAGE, 78350, Jouy-en-Josas, France
Université Paris-Saclay, INRAE, BioinfOmics, MIGALE bioinformatics facility, 78350, Jouy-en-Josas, France
