Introduction to Tidyverse
Module 12
Mahendra Mariadassou 
MaIAGE
Christelle Hennequet-Antier
MaIAGE
June 19, 2023
Better know us

- Open infrastructure dedicated to life sciences
- Computing resources, tools, databanks…
- Dissemination of expertise in bioinformatics
- Design and development of applications
- Data analysis
Tidyverse (I)
Ordocosme in 🇫🇷 with Tidy for “bien rangé” and verse for “univers”
A collection of R 📦 developed by H. Wickham and others at Rstudio

Tidyverse (II)
“A framework for managing data that aims at making the cleaning and preparing steps [muuuuuuuch] easier” (Julien Barnier).
Main characteristics of a tidy dataset:
- each variable is a column
- each observation is a row
- each value is in a different cell

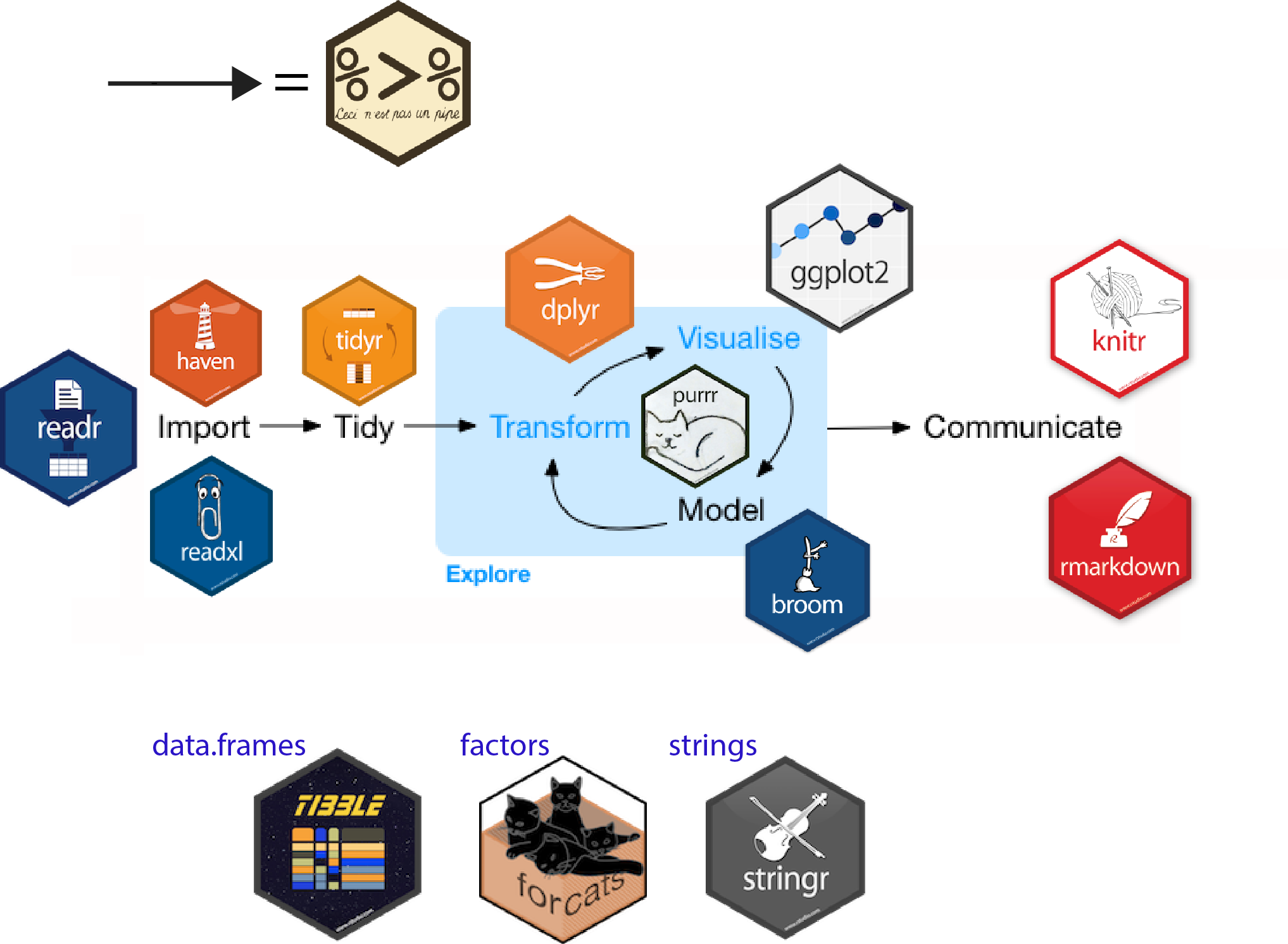
Workflow in data science
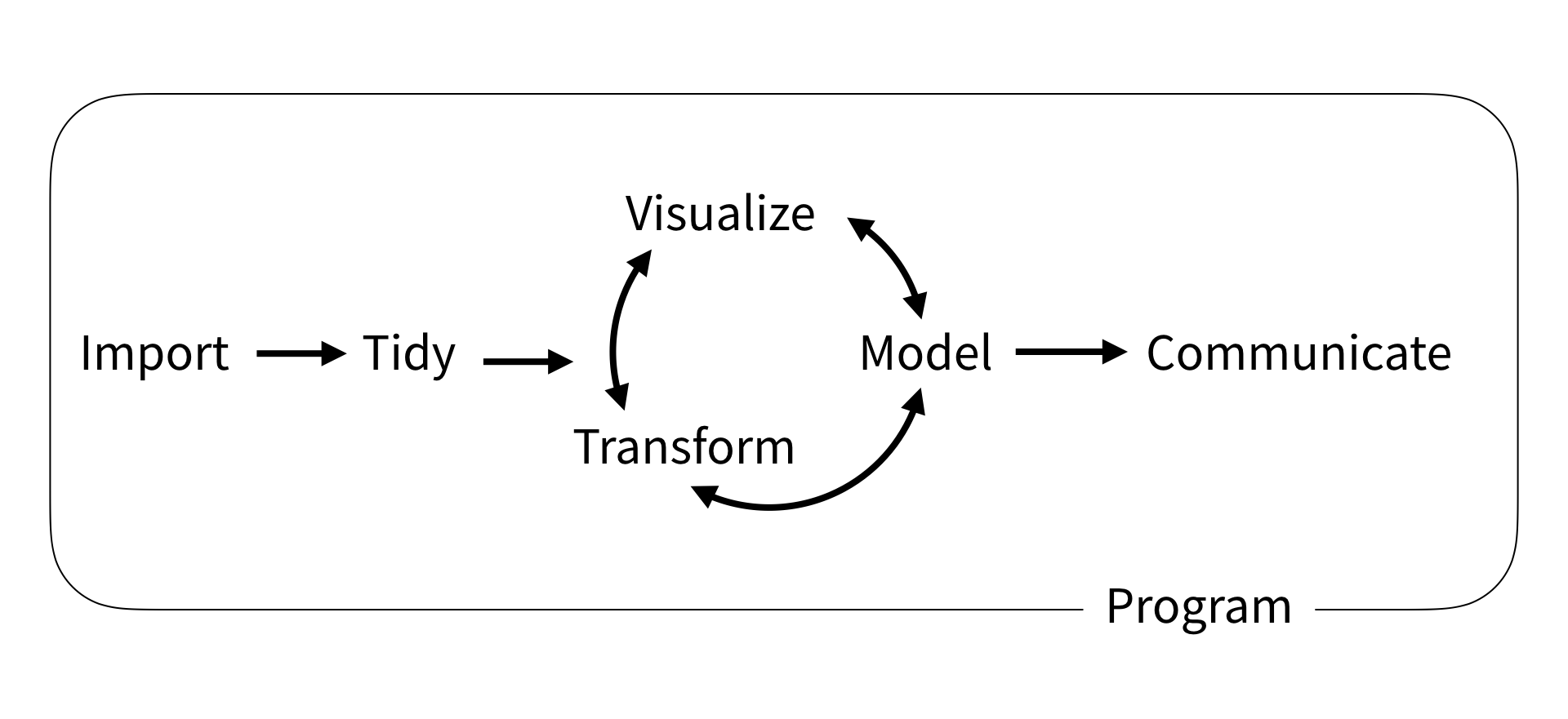
Workflow in data science with tidyverse
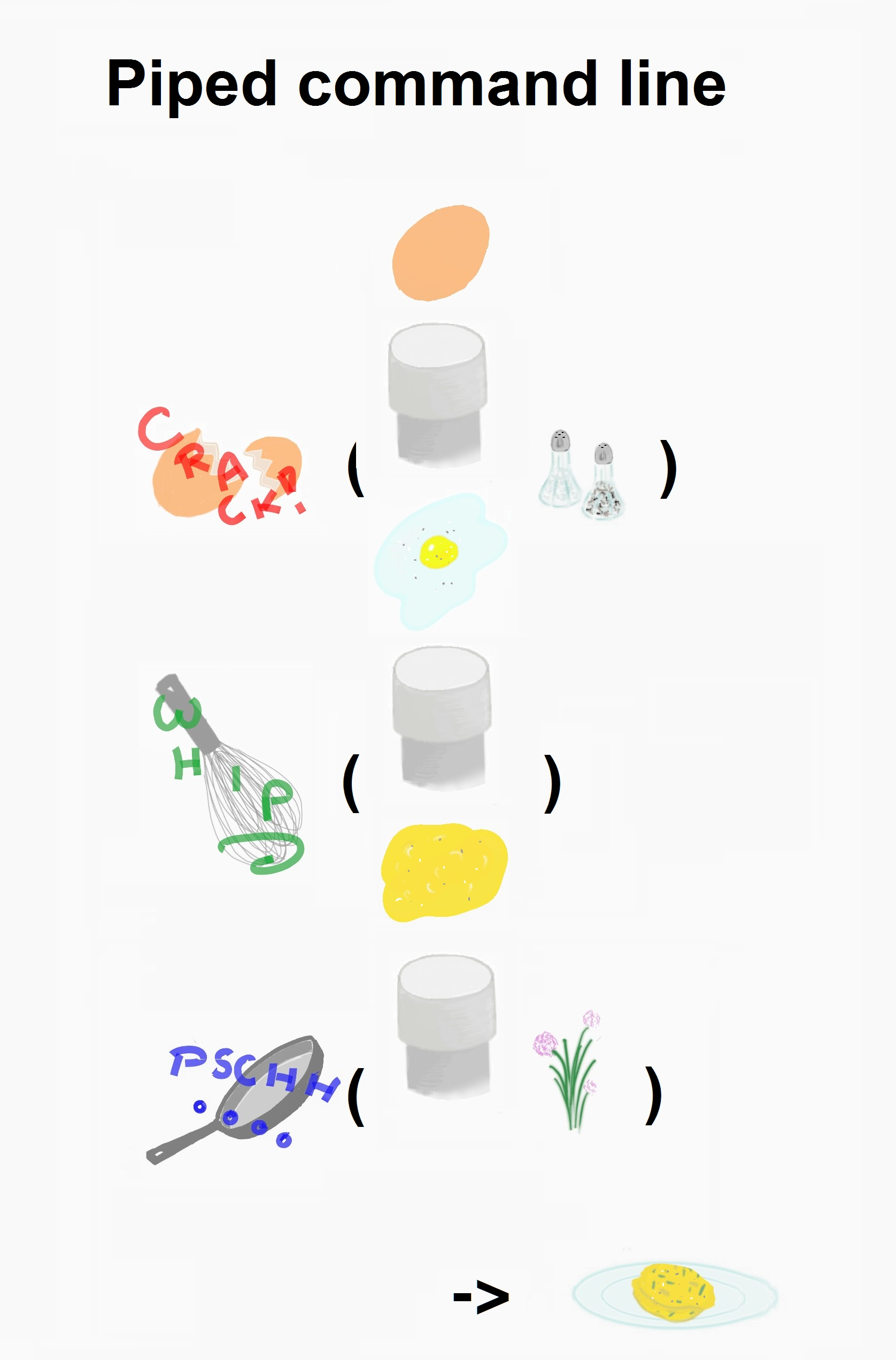
Syntax with pipe
- Verb(Subject,Complement) replaced by Subject %>% Verb(Complement)
- No need to name unimportant intermediate variables
- Clear syntax (readability)
![]()
Base R from Lise Vaudor’s blog

Piping from Lise Vaudor’s blog
Tidyexplain

Long and wide formats
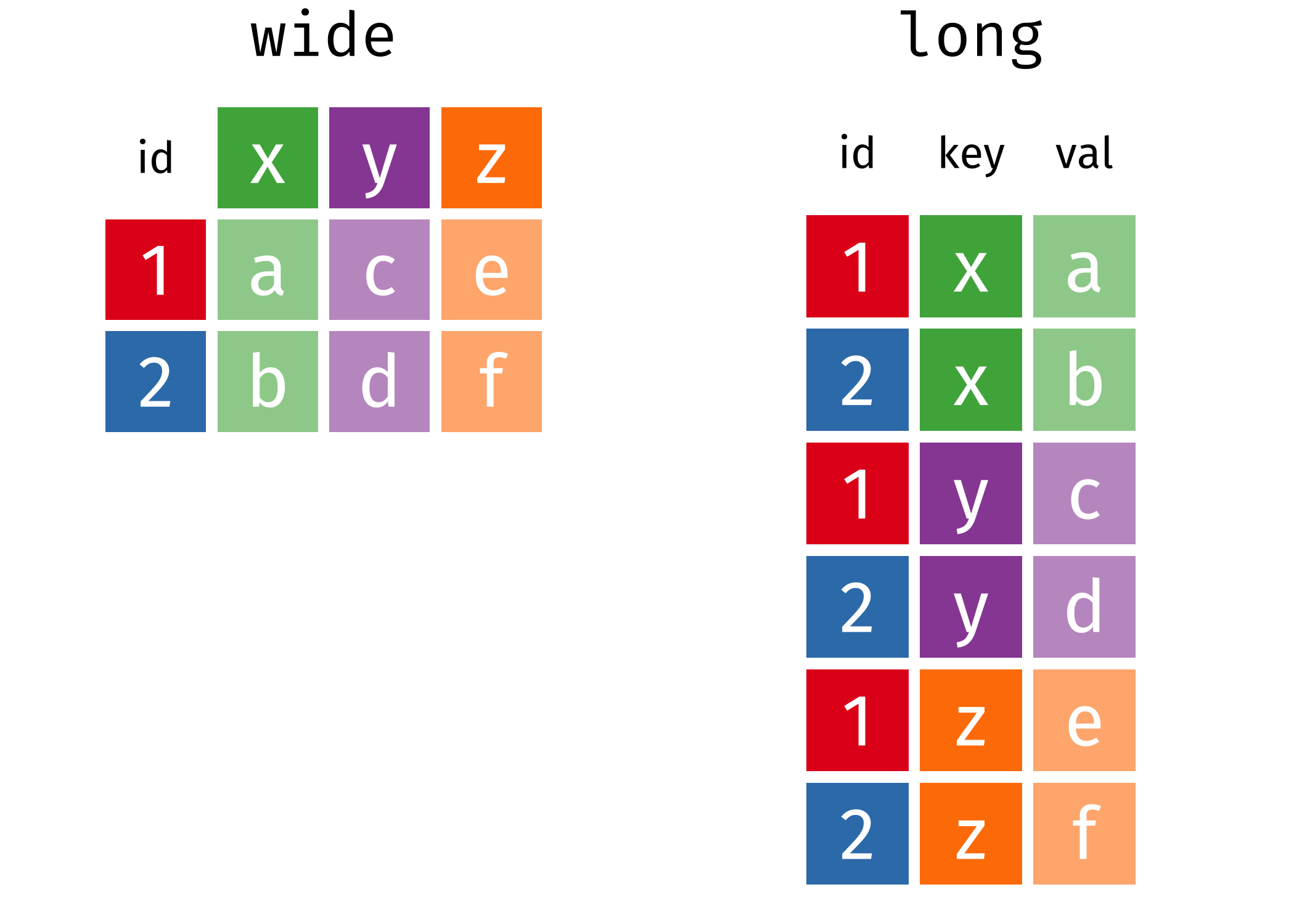
From Long to wide and vice-versa
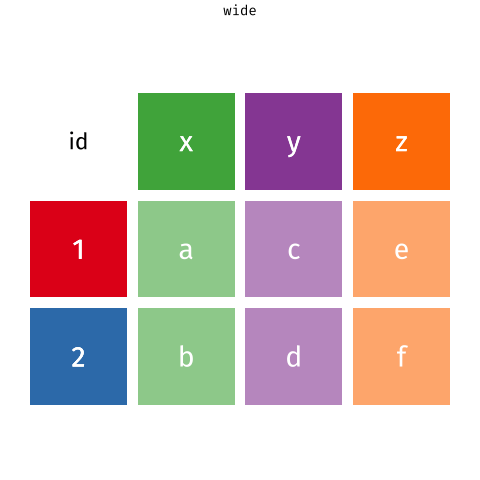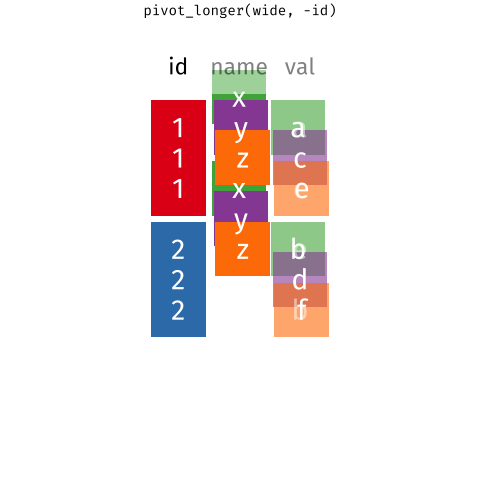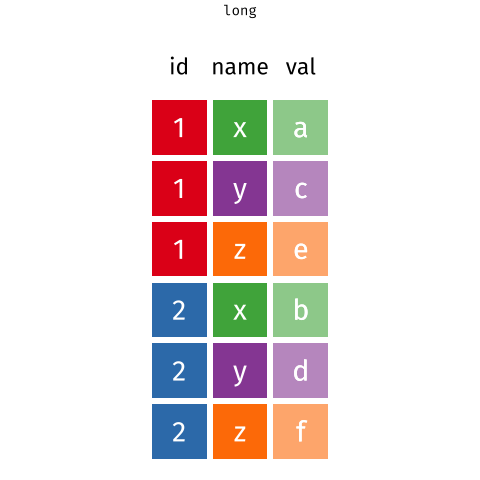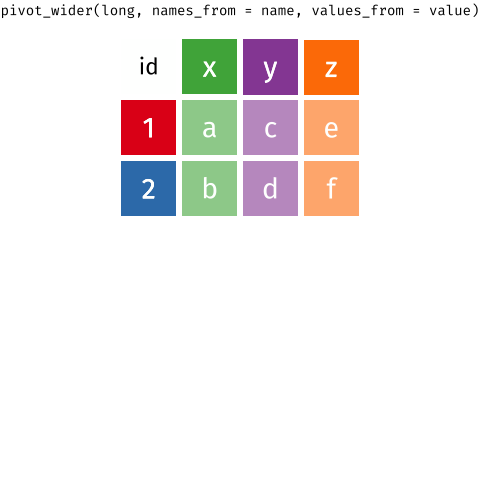
The RStudio Cheat Sheets

