Introduction aux bonnes pratiques pour des analyses reproductibles
Module 25

PROSE & MaIAGE - Migale
MaIAGE - Migale
March 21, 2024
Tout le monde a déjà eu cette expérience
Un article interessant

Un matériel et méthodes décevant

Crise de la reproductibilité
Problème général, “Reproducibility Crisis”
- Remis en avant par les science sociales, notamment la psychologie
- Étendu à l’ensemble des disciplines scientifiques
Mais un problème qui n’est pas nouveau
- Expériences de la pompe à vide au XVIIe siècle (von Guericke et Boyle)

En pratique, qu’est ce qu’être reproductible ?
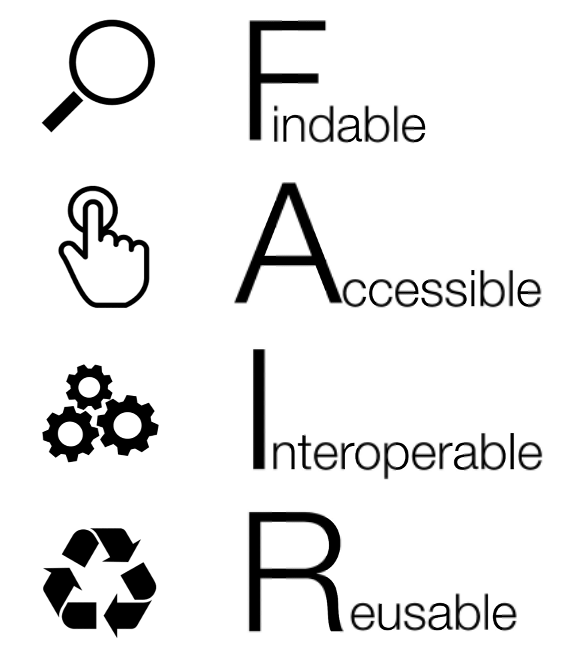
FAIR : un pré-requis à la reproductibilité
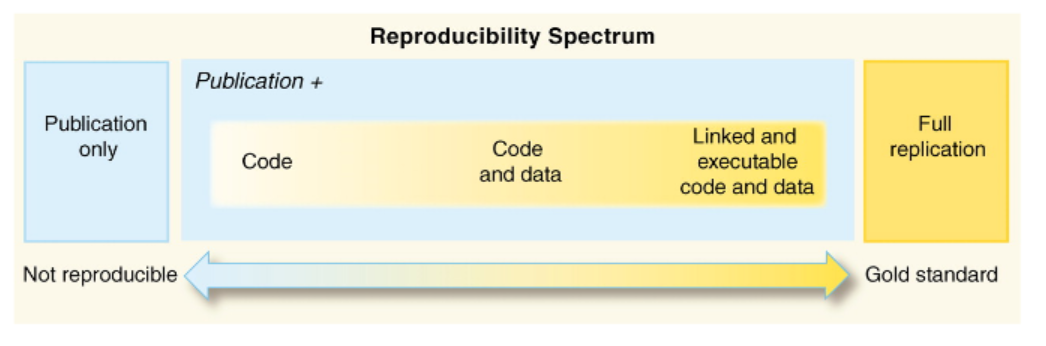
Le spectre de la reproductibilité
[4]
Organiser son espace de travail
[5]
Séparer :
- données
- code
- scripts
- résultats
- Avoir un copie de sauvegarde de ses données
- Mettre le répertoire et les fichiers de données en lecture seule
- Avoir une convention de nommage de ses fichiers
Data management tips (Source : Kira Höffler | PDF)

Pourquoi versionner ses projets ?

→ Suivre l’évolution des fichiers
- garder en mémoire chaque modification de chaque fichier
- pourquoi elle a eu lieu
- quand et par qui !
→ Faciliter le développement collaboratif
- fusionne les différentes modifications
→ Revenir à une version précédente
- et assure une sauvegarde de son travail.
Vocabulaire
- Repository = Dépôt. Dossier contenant tous les fichiers d’un projet. Personnel ou partagé. Public ou privé. Local ou distant (remote).
- Commit = Enregistrement d’un ensemble de fichier à un instant T (= photo)
- Branche = Ensemble chaîné de commits, par défaut la branche principale s’appelle « main »
- Git : logiciel open-source de gestion de version de document. Il est tout a fait possible d’utiliser git pour versionner ses documents sans GitHub.
- GitHub : site web permettant de centraliser en ligne ses dépôts git et facilitant la collaboration sur les projets.

Travailler en commun avec Git et Github :
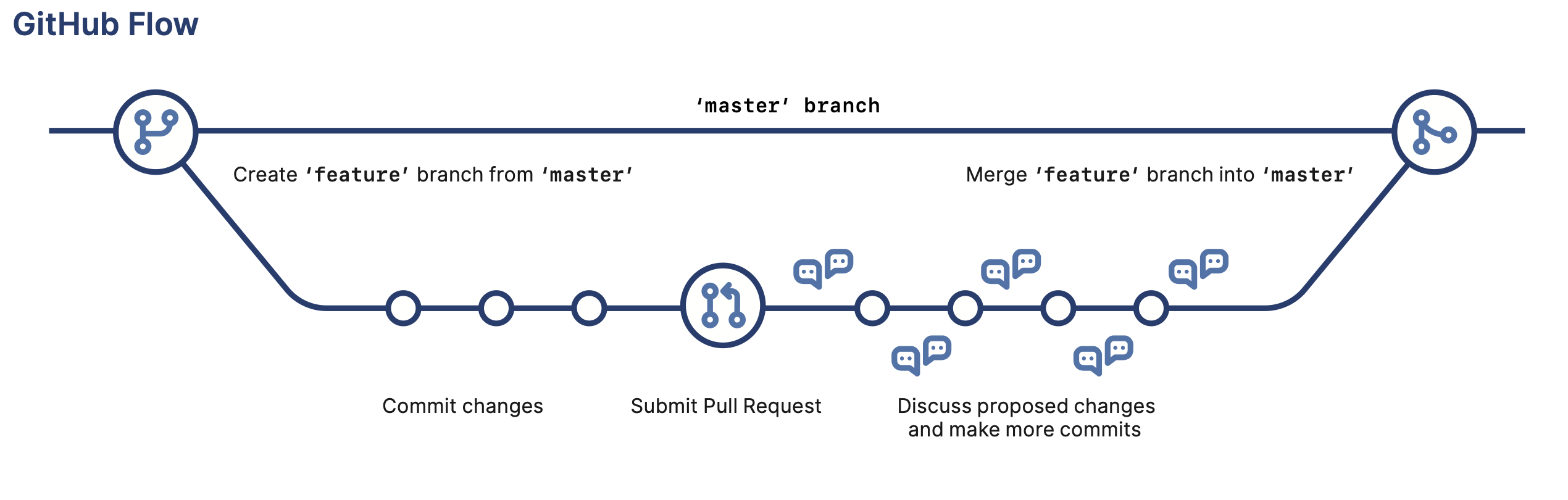
- Branche = version parallèle à la version principale
- Pull Request = demande de fusion des modifications d’une branche vers la branche principale
Documents computationels - Notebook
- Il faut se donner les moyens pour qu’autrui puisse inspecter nos analyses
- Expliciter pour augmenter les chances de trouver les erreurs et de les éliminer
- Inspecter pour justifier et comprendre
- Refaire pour vérifier, corriger et réutiliser

Documents computationels - Notebook
Regrouper dans un unique document: les informations, le code, calculs et les résultats ; pour assurer leur cohérence et améliorer la traçabilité. Tout en étant exportable (ex : html) pour une meilleure portabilité et lisibilité.
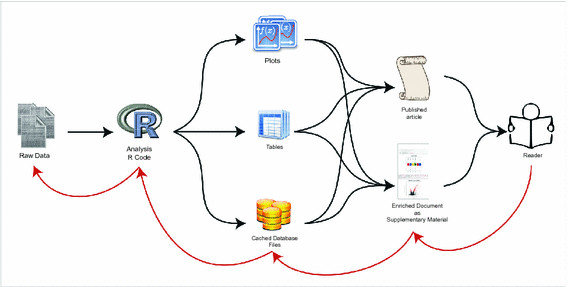
Encore un joli mémo pour R markdown.
D’un RMarkdown à un PDF

 ]
]
Nouveautés : Quarto
Une alternative open-source pour la publication de documents scientifiques et techniques !
- Input :
Python,R,Julia, etObservable - Output : Articles, présentations, livres, sites/blogs, …
- Rédaction et déploiement simplifié

Science Ouverte
Second Plan Nation Science Ouverte (2022)
La science ouverte est la diffusion sans entrave des publications et des données de la recherche.
Elle s’appuie sur l’opportunité que représente la mutation numérique pour développer l’accès ouvert aux publications et –autant que possible– aux données de la recherche.

Plan de Gestion de Données - Quoi ?
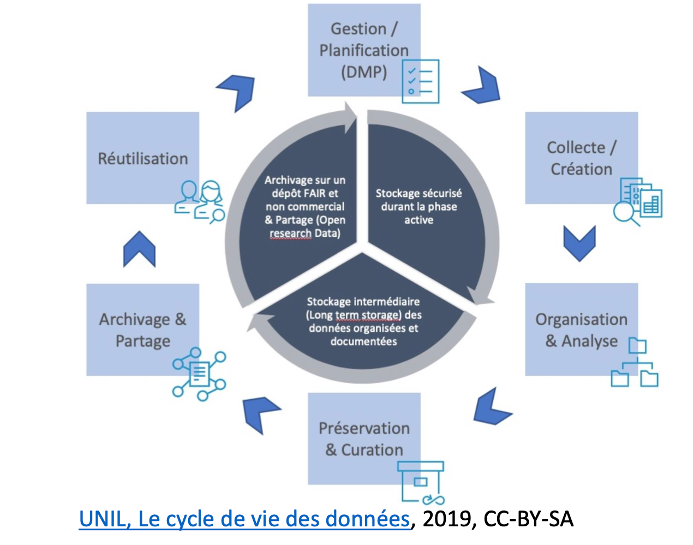
Un document collaboratif qui définit la façon dont les données seront gérées pendant et après le projet.
Objectifs
Penser à toutes les étapes du cycle de vie de la donnée
Avantages
Le modèle vous aide à anticiper l’ensemble des questions et des problèmes qui peuvent se poser par le biais d’une série de questions.
PGD en pratique
Différents modèles (ANR, Horizon Europe) - Un seul document avec 6 sections, 2 à 4 questions par section. - DMP OPIDoR pour organiser l’écriture collaborative

Fixer et partager son environnement (2)

[7]
Gestionnaires de workflows
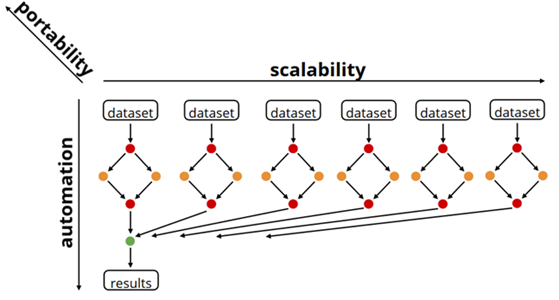
Snakemake ou Nextflow pour définir de façon “simple” et modulaire des workflows d’analyse :
- Parallélisables : les étapes indépendantes peuvent être jouées en parallèle.
- Qui assurent la reprise sur erreur : si on refait une analyse, change un paramètre, seul ce qui doit être rejoué est relancé.
- Portables : un même script peut être joué en local, sur des clusters différents en changeant le fichier de configuration.
- Partageables : un fichier texte versionné.
- Peut gérer pour vous le versionning et l’installation des outils avec conda
Pour aller + loin - Mat & Met
jusqu’où aller dans la reproductibilité ?
- Mat et Met électroniques :
- Galaxy Pages
- Gigascience, GigaDB :
- “GigaScience aims to revolutionize publishing by promoting reproducibility of analyses and data dissemination, organization, understanding, and use.”

Au final, toujours se poser la question du rapport coût / bénéfice.
Épilogue

Comment mettre en forme et structurer simplement un document texte ?
→ avec un balisage faible tel que Markdown